(Това е лекцията ми от OpenFest 2018. Разказът не се получи много добре, понеже със задачите преди това забравил половината от нея, надявам се текстът да е по-добре. Също така мисля да публикувам кода за нея, понеже в него се появиха разни интересни неща)


Иска ми се да разкажа за OpenFest. Минаха много години и се събра много история, много идеи, много последствия – хубаво е да се знаят и да е ясно защо трябва да се продължат.
Лекцията не претендира за голяма изчерпателност, понеже ще отнеме два дни и малко ще попречи на останалите лекции :)
Отсега да предупредя, това е една много разхвърляна лекция, с подъл спамерски елемент.

Първият OpenFest беше 2003та. Започна като събитие за свободния софтуер, и се проведе в много градове из страната, като беше по едно (спрямо сегашните мащаби) малко събитие във всеки град.
В началото се движеше от съвсем малко хора, беше зората на free software/open source движението и ентусиастите не бяха много.
До преди това основното подобно събитие беше един малък семинар в Стара Загора всяка година, на българската Linux User група.

Това е една снимка на залата от първия openfest, издирена някъде от архивите на linux-bg.

А това е едно от първото ни споменавания във вестник, мисля, че беше Пазарджишки. Благодаря на човека, който го е снимал/сканирал:)

Учудващо, но идеите не са се променили много през годините. Има много изписани текстове, с дълги или не толкова дълги думи, които да обясняват целите на феста, но аз мен винаги в общи линии нещата са се характеризирали със следните две думи:

Две прости ясни думи. Тълкуването им може да се остави на въображението ви :)
Каквото и друго да измисля, в общи линии се включва в тези неща.

Ако някой направи tag cloud с темите, вероятно ще се стигне до горните няколко области. Разбира се, свързващото нещо беше Linux, понеже олицетворяваше всички тези неща в някакъв вид, и беше нещото, което ползвахме, да си вършим работата или да правим разни интересни неща…

Имало е всякакви интересни теми и хора на openfest през годините. Избрал съм няколко, за останалите трябва да се заровите в програмите или някой да напише подробна история :)
Останал ми е спомен от хората от wikipedia, които идваха да говорят на OpenFest – и за техническата и за не-толкова техническата си страна, докато още не бяха един от най-големите сайтове в internet-а.
Една от инициативите на общността беше (и още е) свободния софтуер в държавната администрация – употребата му, какви лицензи за какво да се купуват и всякакви такива теми. Не мисля, че мога да си спомня всичките неща, през които преминахме, но като един краен резултат (за който много голяма отговорност носи Божо Божанов) имаме закон, който задължава фирмите всичкия софтуер, който се пише за държавата да е open source и да се публикува свободно.
Дори вче имаме резултат от това :) Наскоро беше публикуван кодът на новия портал за отворени данни, който е от две части, и искам да обърна внимание на едната:

Ако нямахме този отворен код за държавния софтуер, нямаше да сме наясно и да можем да направим каквото и да е за код като по-горния. Оставил съм отдолу link, целият код е забавен, може да видите и history-то му, ще се забавлявате още повече. Може би е време за един по-организиран community audit на подобен код, след като имаме възможността.
И е интересно дали някой може да провери каква част от кода е copy-paste от stackoverflow.

Друга тема, с която се занимахме беше инициативата в Европейския съюз да се приемат софтуерните патенти. Който си е имал работа с писание на софтуер в щатите знае за какво става въпрос, който не – миналата година имаше лекция от Пейо Попов по темата как са се борили с един патентен трол по един тривиален софтуерен патент. Много съм щастлив, че инициативата се провали при нас такива патенти няма.

(не се сдържах за снимката. Спокойно мога да кажа, че това изглежда по-смисленото приложение на IoT, вместо многото устройства, които в наши дни се използват основно за източник на DDoS атаки)
Имаше IoT лекции на openfest преди да съм чул термина, и хората дори се забавляваха да си запояват/подкарват такива неща в рамките на феста (и почти традиционно да успяват да убият мрежата по някакъв начин).

Около това ми се иска и да спомена workshop-ите за запояване, които са доста свързани – една година Цветан Узунов от Olimex си хареса един ъгъл в interpred, извади едни поялници и два дни хора седяха и запояваха различни неща. Искам много да му благодаря за започнатата традиция :)
И да, съвсем съм наясно, че запояването дори бе неше основното – основното беше подкарването на всичките тия компоненти да вършат различните интересни (и странни) задачи, които им бяха измислили.
За съжаление нямам снимка на съвсем първото такова събитие, за това съм сложил снимка от едно от по-скорошните.

Извън техническите и легални неща, преди няколко години направихме лекция за депресията и отражението и в IT обществото. Наскоро забелязах как вече хората не се притесняват да говорят по темата и да възприемат депресията като сифилиса, та ми се ще да вярвам, че и ние сме имали някакво влияние за това :)

Разбира се, имаше доста промени през годините – местихме се в различни зали, нямахме медийно отразяване, защото или имаше избори, или предния ден застрелваха някого (беше се случило две години подред).
Интересно за някои хора може да е, че Интерпред беше мястото, от което се изнесохме, защото наистина ни отесня. Мисля, че още не сме публикували колко човека дойдоха, понеже има сериозен шанс да ни глобят…
В екипът идваха нови хора, стари решаваха да си починат, после се връщаха.
Текущите цели се меняха, като може би най-яркия пример е колко време беше отделено на кампанията срещу софтуерните патенти. Има и много други примери, но с годините съм ги забравил и вероятно трябва да се изпие много бира с много хора, че да ги съберем всички :)
Обаче, без да се усетим, стана нещо интересно…

Изведнъж се оказа, че сме победили. Когато започвахме, свободния софтуер се считаше за хобистка история, някакво забавление и нищо сериозно, разни хора се подсмихваха и обясняваха, че това не е сериозна работа и да вземем да правим нещо смислено.
В момента…

В момента звучи съвсем нормално и очаквано, че най-използваните мобилни и cloud операционни системи са Linux и Linux-базирани. Базата данни, която използват всички, включително почти всички мобилни устройства (не само android) е sqlite и в общо линии не мисля, че в наши дни е откриваем компютър или телефон без нея.
Ако в наши дни някой седне да разработва софтуер, почти без изключение съдържа доста open-source компоненти. Казвам почти, понеже сигурно някой ще открие нещо древно от времената на Cobol, което да няма, но па всичко, което се използва в наши дни е така, и присъствието на git във visual studio code е доста добър индикатор….
В общи линии хората разбраха, че предимствата на свободния софтуер и на отворените стандарти надминават имагинерните проблеми от тях.

Това не ни остави без причина да съществуваме – винаги някой е против отвореността и се намира някоя кауза (например чл. 13 и няколко други на директивата за авторско право на Европейския съюз, която е поредния опит да се наложи цензура в Internet). Отбелязал съм разни проблеми, които очаквам да са ни теми в бъдеще:

DRM-ът не изчезва, продължават опитите да бъде наложен по някакъв начин и интегриран в света ни, което си остава едно от най-гнусните посягания на софтуерната свобода.
Всичките code-of-conduct тип проблеми няма да стават по-леки, както ни показа последната случка с Linus. Искрено се надявам да ги надрастнем… Мариян имаше предложение тази година да организираме панел по темата тук, но на мен ми призля. Не съм сигурен дали бях прав да се противя, и се надявам някой с по-здрав стомах и желание да успее да го направи (и да се получи смислено).
Софтуерът ни расте главоломно и става невъзможен за разбиране и поддръжка. Отдавна сме минали границите на разбираемост, и ще ни е трудно да се върнем в тях, но виждам някакви опити.
Internet-ът става все по-централизиран, което поставя всякакви ограничения на технологиите и улеснява и подслушването и анализа на информацията. Не знам колко години ще са ни нужни, за да осъзнаем последствията от технологиите, за които говори Едуард Сноудън, и вероятно ще са нужни още толкова, за да разберем, че не са спрели да се развиват.
В последните месеци не чета новини, но не мисля, че има големи разлики в действията на политиците спрямо internet, софтуерът и технологиите. Генералното ми очакване е, че ще трябва да продължаваме да се борим с всякакви глупости, които ни пречат да работим, живеем и т.н.

Идеята на събитието не се е променила особено, въпреки промените в екипа и изминалото време. Смятам, че идеите са достатъчно силни, че да могат да мотивират достатъчно хора, които да случат всичко.

За всяко събитие е полезно да има нови хора, и препоръчвам на всеки, който има желание, да се обади.
Преди да продължа с причните да се включите, една скоба – не е задължително да сте част от екипа, за да участвате по някакъв начин.
Почти всяка година се намира някой да се оплаче (основно без причина), че нямало добри лекции. Отговорът е винаги – като имаше CfP, къде спахте? Има много хора в нашата държава (и наблизо), които се занимават с интересни неща и могат да ги разкажат, но ги знаят само те и няколко близки приятели. Ако случайно сте от тези хора или от близките приятели, припомняйте им в началото на септември, че има такова нещо като OpenFest :)
Това важи не само за лекции, но и за workshop-и, има много неща, които могат да бъдат показани и на които посетителите могат да се научат.
И сега към причините:

Не е лесно да се оцени крайния ефект от OpenFest. Основното, което имам са някакви мои преживявания, от типа “чух на openfest за това и се занимавам с него”, за разни лекции и разни хора. Мисля, че всяка година има хора, идващи за първи път, които се прибират с пълни глави и се чудят кое от всичките неща, които са видели, да захванат.

На колко от вас ви харесва светът, в който живеете? Вдигнете ръка.
За всички, които вдигнаха ръка – свържете ме с дилъра си:)
В някои отношения нещата са по-добре, отколкото преди 20 години – сега например доста по-малко се стрелят по улиците.
От друга страна обаче, технологиите и злоупотребата с тях, концентрирането на много отговорности в една компания и т.н. са доста притеснителни.
Извадих няколко заглавия от новини(докато писах лекцията, на random, от един ден), за да илюстрирам. Преди месец-два съвсем бях спрял да ги чета, погледнах колкото да намеря нещо илюстративно, и никак не ми беше трудно…
Та, в светът, в който живеем:
– 62% от сайтовете използват ужасяващо строшена технология
– огромна компания, известна с повреждащото си въздействие купува друга средно вредна компания, която обаче е работодател на много сериозна част от разработчиците на ядрото и други инфраструктурни технологии
– Пак да си припомним, всеки от нас носи по едно-две проследяващи/подслушващи устройства, които м/у другото стават да правим обаждания и за browser-и. Статията конкретно е как няколко разузнавания послушват американския президент, и съм склонен да кажа, че нищо от това не е особено учудващо за който и да е, който е писал софтуер за такива устройства.
– Хората (не само в Русия) им се пробутва безплатен интернет, за да бъдат продавани.
Има начини да се борим с това. Образоването на хората, говореното по темата, привличането на нови хора в това е от възможностите на OpenFest, и е нещо, в което може да се включите.
Това като цяло произхожда от един момент, който за мен е очевиден, но по някога се притеснявам, че не е така за всички:

Ще се направя на стар и ще кажа, че не е задължително да ни е гадно. Виждал съм времена, които са били зле, виждал съм и по-добре, виждал съм нещата да се променят и в едната и другата посока и общият ми извод е, че не е нужно да ни е гадно, няма някаква вселенска повеля, която го изисква. Можем да направим нещо по въпроса и в общи линии си зависи от нас да го направим.

И да минем към нещо по-приятно.
Може би само на мен ми е толкова интересно това, но едно от нещата, които най-много са ме радвали са, че си правим сами каквото можем. Всякаква инфраструктура, като мрежа, wifi, видео streaming, понякога ток – имаме сериозен знаещ екип, интересна техника и всякакви забавни неща, които правим с нея.
Сайтът ни за submit-ване на лекции сами сме го писали, този за гласуване е пригаждан, сайтът на събитието (който по принцип е един wordpress) е сериозно дописван от нас и може да се види цялата му история в github.
Изобщо, техническата ни част е рай за хората, които обичат предизвикателствата :)

(тези неща Мариян ги спомена след лекцията, реших, че е добре да ги включа)
Разбира се, не всички екипи са толкова технически, но са също толкова важни.
Екипът “Логистика” отговаря за това всичката ни нужна техника (която никак не е малко) да стигне от различните места, на които се намира, до самата зала, и после да се изнесе. Грижи се за положението на всички физически неща, както и за събирането ни на лекторите от летището, особено като носят десетки килограми странни неща с тях.
Медийният екип се грижи за цялото медийно покритие на събитието и обявяването на нещата преди него – статии в сайта, twitter, facebook, събиране на информация от лектори и т.н.. Този екип е едно от местата, в които прохождащи журналисти/студенти могат да се занимават да пишат и отразяват нещо реално и случващо се.
При всички доброволци си имаме и екип, който се грижи за тях – да са облечени, нахранени, да има къде да си починат и всички подобни неща. Като едно тяхно действие мога да кажа как миналата година бяхме предвидили за Team room едно от помещенията до NOC-а, в мазето (със собствена тоалетна). Дойде екипът volunteer support, погледна, каза “това е твърде депресиращо” и заради тях сега екипът може да си почива в стая с прозорци :)
(аз не разбирам тия неща, но явно на хората им харесва)
Екипът рецепция е един от най-видимите и доста натоварен – голяма част от хилядите ни посетители минават през рецепцията по един или друг начин.
И екипът хералди се занимава да представя лектори, да ги прекъсва като им свършва времето и всякакви такива забавни неща.
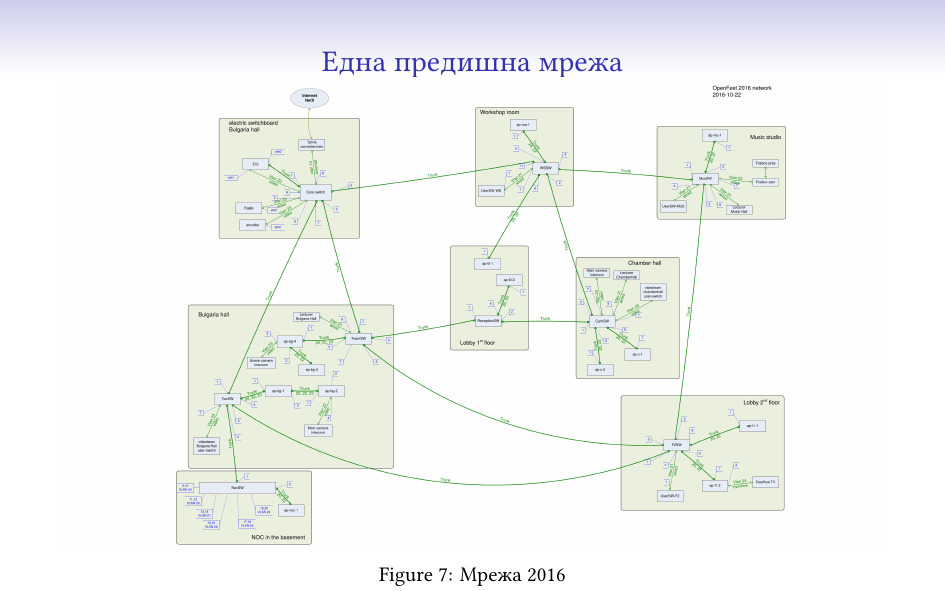
Това е схема на мрежата ни, докато бяхме в зала “България”. Понеже там е много красиво и няма никаква инфраструктура, трябваше да опънем около километър кабели (и 2 метра оптика, щото едни медни GBIC-и се бяха счупили), съответно мрежата е направена да издържа на прекъсване на което и да е трасе и има в себе си няколко цикъла. Също така тази мрежа е пример, че може да се подкара MSTP в мрежа с Cisco и TP-Link устройства.
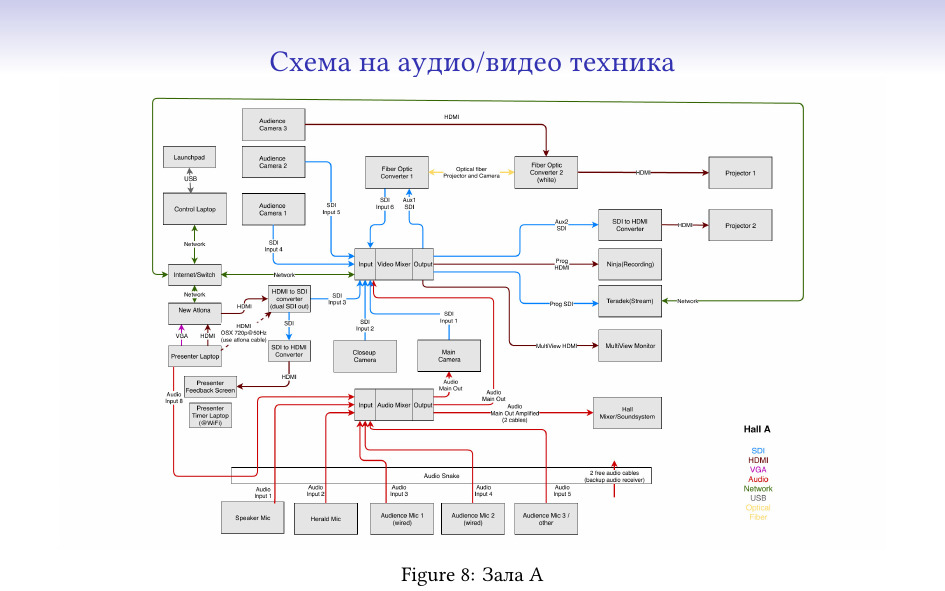
Това е как ни изглежда setup-а за тази година за залата, в която се намираме в момента.

… а това е по-артистично нарисувана схема на setup от предишни години.
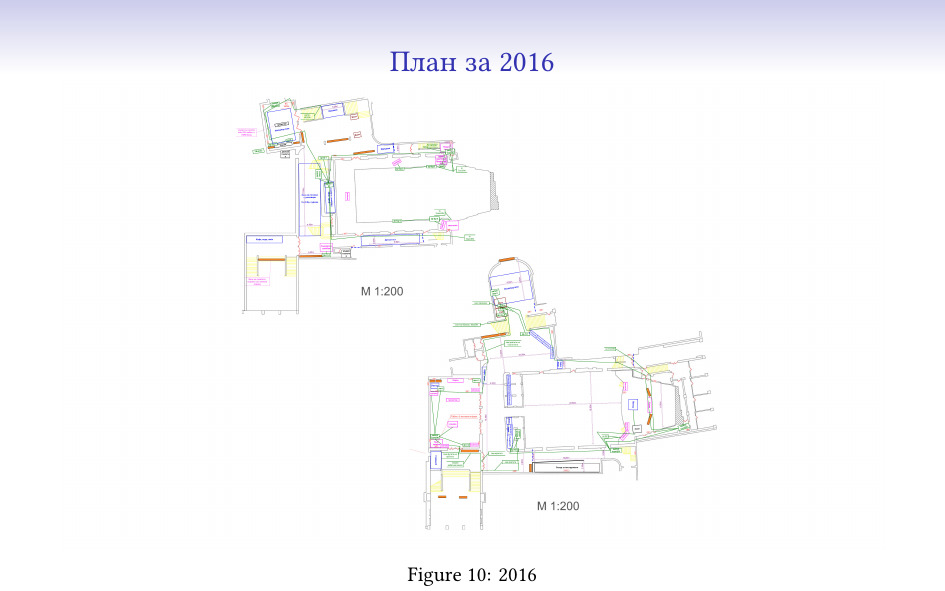
Това са плановете за разпределението на площите през 2016…
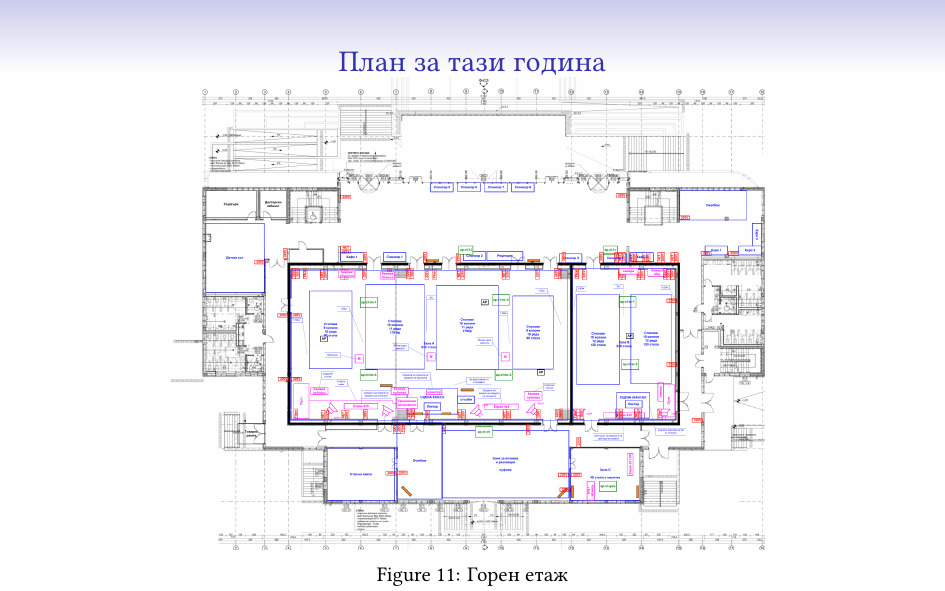
… а тези – на етажът, на който се намираме в момента.

За хората, които обичат да обитават мазета – това е NOC-а ни в зала България,

а това – текущия в ТехПарка. Има напредък, но пак си е мазе и е много удобно за всякакви хора, на които NOC-овете са нормалното обиталище :)

Това е една снимка на техниката ни за 2015, в общи линии може да видите почти цялата ни мрежа, разпъната на едно бюро, заедно с някаква част от wifi AP-тата.

А това е една хубава снимка от по-малкия ни video setup.

И скоро не ни се е налагало да си прекарваме по странен начин internet-а, но искам да покажа как нищо не ни е спирало – тук може да видите какви средства сме използвали за стабилизация на антена…

Една година в петъка преди openfest бях започнал да се разболявам. В понеделник бях съвсем здрав, и изобщо не си спомням да съм боледувал, имам спомен само от много тичане и задачи …
Мислех си да опиша екипа, но няма да ми стигнат нито думите, нито времето. Събрал съм малко снимки, колкото горе-долу да илюстрирам, но си казвам отсега, че изобщо не стигат:)

Това е една от най-първите снимки, когато даже имахме статуетка, която давахме на някой за принос в областта на свободния софтуер.

Тук седим и конфигурираме мрежа през 2005. Вече е минало достатъчно време да кажа спокойно, че човекът от ИЕЦ беше готин и просто каза – ето ви switch-а, настройте го както си искате.

Този сигурно някои от вас го познават…

Тук може да видите мрежар в нормалното си обиталище.

Екипът от 2013 (когато започнахме традицията всички да се покажат един път на сцената).
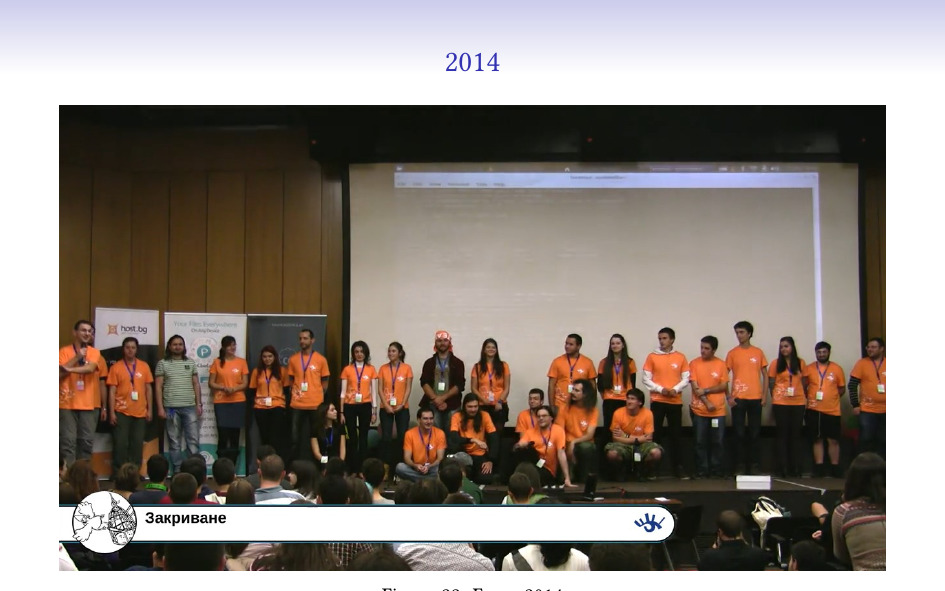
Екипът от 2014 (когато започнахме друга традиция, екипът да има отличаващи се тениски, за по-лесно ориентиране на посетителите).

Екипът от 2015 (това, което виждате най-вдясно са един малък духов квартет, който свири Имперския марш).

…а 2015 дори успяхме да усмихнем Яна, въпреки цялата лудница.

Тук има някакви хора, които мъкнат…

… и разни въоръжени такива. Ако не сте виждали хайдутин с пистолет и радиостанция, това ви е шанса.

Екипът от 2016.

Екипът от 2017.

И от 2018, може да видите как час от екипа стои в петък вечер в сървърното и оправя проблем, за да имаме internet на следващия ден. От другата страна на телефона съм аз, и много се зарадвах, че някой е снимал ситуацията, особено с човека, който се държи за главата.

И искам да завърша с една благодарност към всички, които през годините са допринасяли по някакъв начин за OpenFest. Събрах доколкото можах всички имена (надявам се не съм пропуснал никого)
Видеото, което пуснах.
{kind=link}
{kind=link}