И ето го описанието на мрежата на openfest. Като цяло изглежда като проект за някой студентски курс по мрежи, няма нещо особено сложно или странно в него, описвам го основно за любопитните хора. Аз ще разкажа за жичната мрежа и топологията, Петко за wireless-а (като намери време и му писне да му мрънкам).
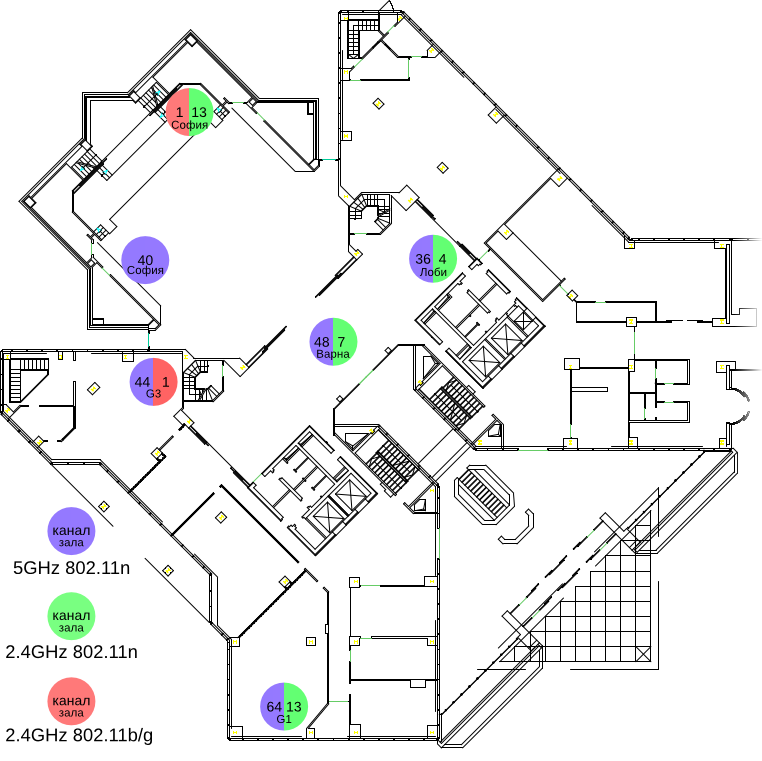
Като за начало, ето генералната схема, в pdf и vsd. Правих схемата на visio, понеже съм му свикнал и още не мога да му намеря еквивалент (а се оказва, че libreoffice вече го отваря).
Топологията беше следната: в “ядрото” (никаква идея защо се казва така) на втория етаж в Interpred влизат кабели до всички нужни зали. Там по принцип има switch на mtel/spnet/каквото-е-там, в който влиза връзката навън и самите зали.
Ние си сложихме там сървъра и един гигабитов switch (core-sw, cisco 3750). В него преместихме кабелите до всички нужни зали, а сървъра (който ни играеше и router) свързахме към техния switch за uplink, и към нашия switch по два порта за streaming vlan-а и за клиентите. В залите, където имахме wi-fi access point-и слагахме managed switch, така че да можем да си занесем дотам двата нужни vlan-а (management и този за потребителите), където имахме камери – също.
Имахме следните vlan-и в мрежата:
600 – management (за нашите си устройства), 10.0.0.0/16
601 – wifi, 10.1.0.0/16 и 2a01:288:4000:32::/64
602 – wired (потребителски портове по switch-овете), 10.2.0.0/16 и 2a01:288:4000:33::/64
603 – streaming (наша техника, пускаща суровите потоци с видео), 10.3.0.0/16
604 – TV (overflow-ове – телевизори и т.н.), 10.4.0.0/16
Толкова голяма мрежова маска за ipv4 при rfc1918 адреси е ок, понеже фоновия трафик от сканирания от internet-а го няма, че да бълваме broadcast трафик постоянно. Имаше проблем с друго, който ще опиша по-долу.
Имахме ipv6 само за потребителските мрежи, по мои наблюдения доста от нашата техника има проблем да си говори с тоя протокол все още, а мотото на setup-а беше “минимални рискове”.
Използвахме нормално per-vlan STP, като беше спряно за VLAN-а на wifi-то, а всички портове бяха в portfast (или какъвто-е-там-еквивалента-извън-cisco) режим. Радвам се, че не ни се наложи да борим цикли или каквото и да е, свързано с него…
Адреси се раздаваха по DHCP за ipv4 и по RA за ipv6.
За да намалим натоварването на външната връзка, със split dns заявките за ip адреса на stream.openfest.org им се отговаряше с адреса на локалния сървър, където имаше същите потоци.
Самия restreaming setup изглеждаше по следния начин:
Трите камери/streamer-и изпращаха до сървъра потоци на голям bitrate/разделителна способност – двете по-малки камери директно HDV потока по UDP, 1080p на 25mbps, setup-а от зала София – 1080p на 5mbps, H.264. На сървъра се reencode-ваха до два формата и се пращаха до големия restreamer (който имаше 10gbps порт) и до локалния сървър, от който също можеха да се гледат. За да няма смесване на този трафик с каквото и да е, всичката A/V техника си имаше отделен VLAN, който беше отфилтриран, така че да не може да влиза в него чужд трафик.
Понеже нямах много вяра и на overflow техниката (и е тривиално да се DoS-не raspberry pi) всичките телевизори бяха в собствен VLAN. На практика, имаше firewall който казваше, че трафик от потребителските мрежи може да излиза само от eth0, не можеше да ходи по нашите vlan-и (600,603,604).
Няколко думи за мрежовата ни техника:
core-sw и sof-pocket бяха две гигабитови cisco-та от netissat (любими switch-ове са ми това, работят идеално, ако се ползват правилно);
quanta беше домашният switch на Мариян, 48-портов гигабитов manageable;
reception-sw беше linksys SWR224G4, който заедно с един SRW2016 (двата от Благовест) ми изпили нервите – не му работеше web контрола, менюто, дето се виждаше по telnet не можеше да настройва VLAN-и, и накрая се оказа, че ако човек се логне, натисне ctrl-z и пусне lcli, там се появява едно доста използваемо cisco-подобно cli, от което всичко става лесно (думи не могат да опишат колко съм благодарен на тоя човек);
Няколко switch-а по залите бяха TP-Link SG-3109 (дойдоха от Unex през StorPool), и направо ми спасиха живота – малки 8-портови manageable, със сериен порт, със същото cli като lcli-то на linksys-а, направо песен за подкарване (чак ми се иска ако намеря такива на нормална цена, да купя 5-6, ще са незаменими за някои събития);
още едно 3750 (от Леков), което отиде за една от залите, понеже дойде в последния момент;
един DLink (от Благо), който замести linksys SRW2016 (пак от Благо), като unmanaged switch за стаята на екипа.
Като цяло крайни потребители се закачаха само в стаите за workshop-и и в team стаята, както и лектора в зала G1 (а трябваше и в другите, ще знаем за догодина).
Следват малко картинки, след което ще разкажа как протече работата на мрежата и какво трябва да направим догодина:
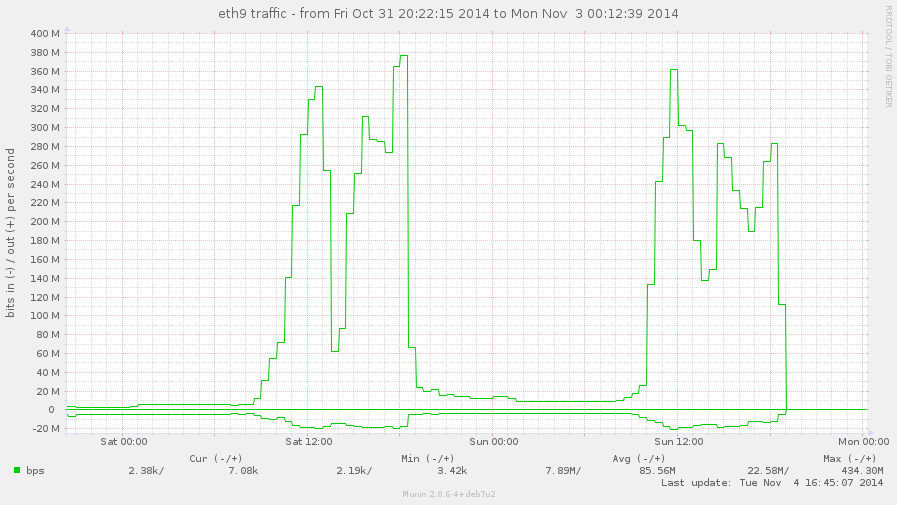
grendel (restreamer-а ни, който ни дадоха Delta.bg):
eth9 – сумарен трафик на порта, през който се stream-ваше за света;
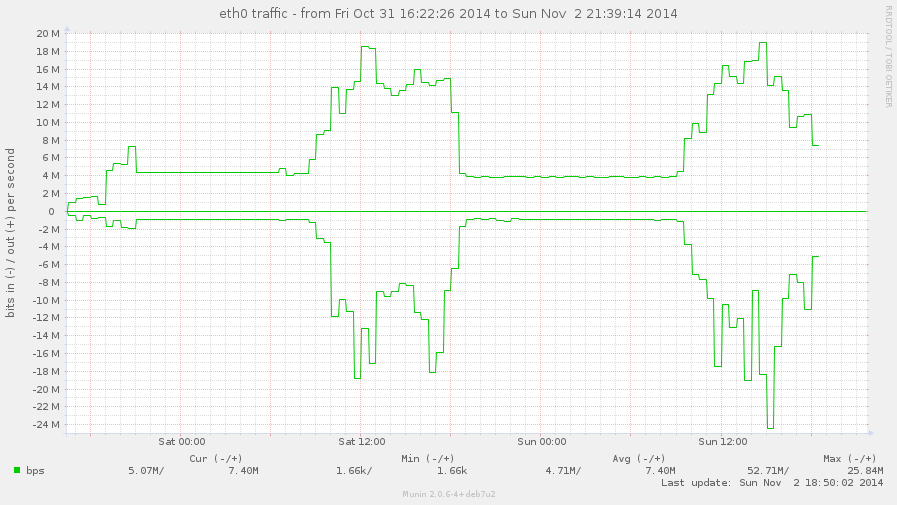
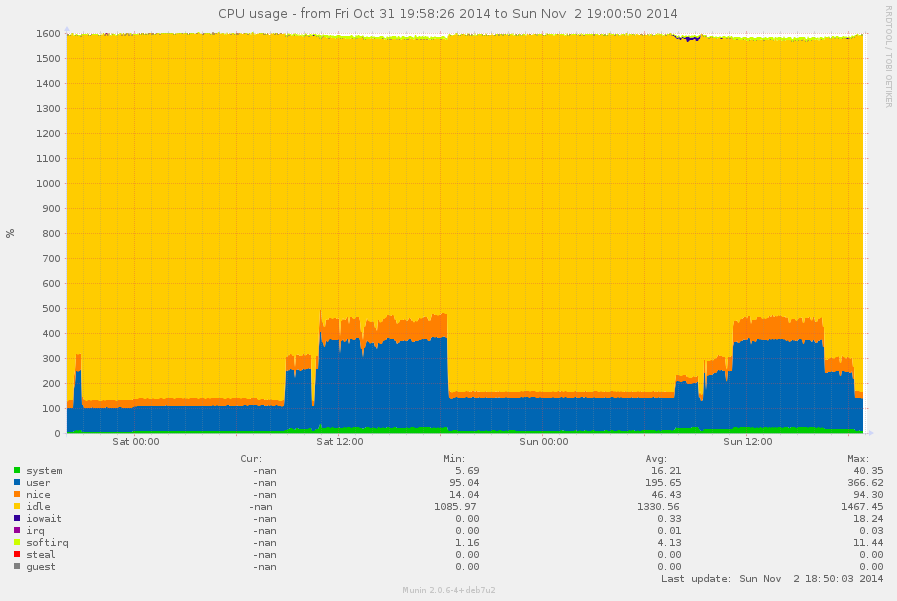
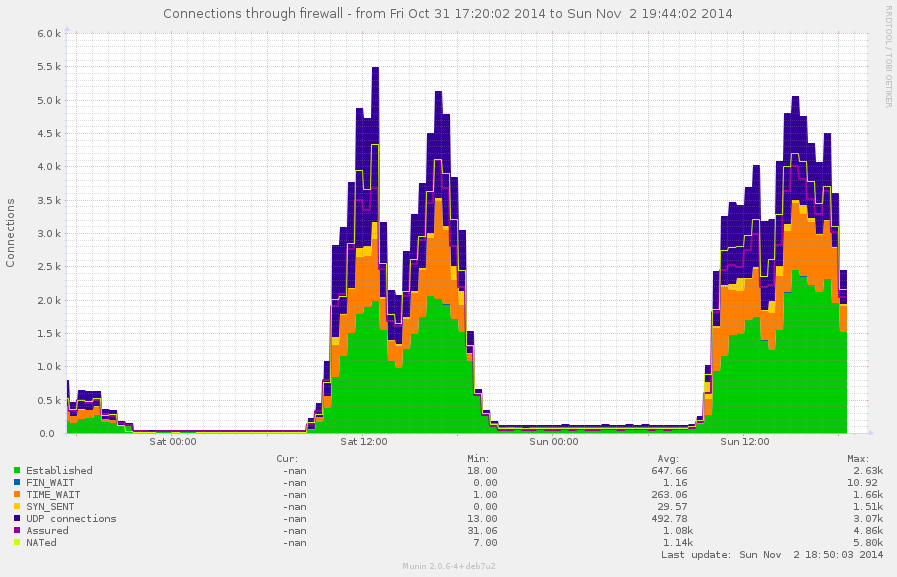
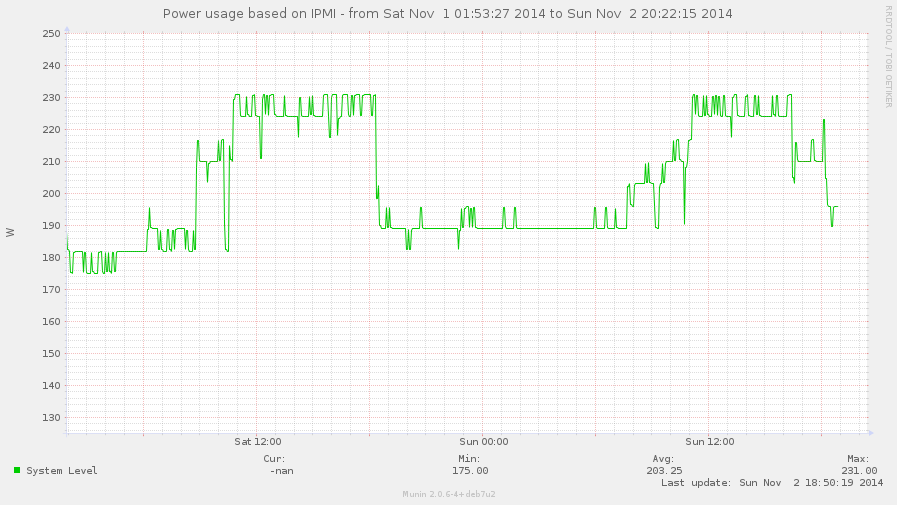
router (eagle):
CPU;
eth0, uplink навън;
connection tracking – статистика по типове връзки;
Power – колко мощност е дърпало захранването на сървъра (не е много смислено, но е забавно);
И от два switch-а, понеже за другите не ми остана време да пусна cacti:
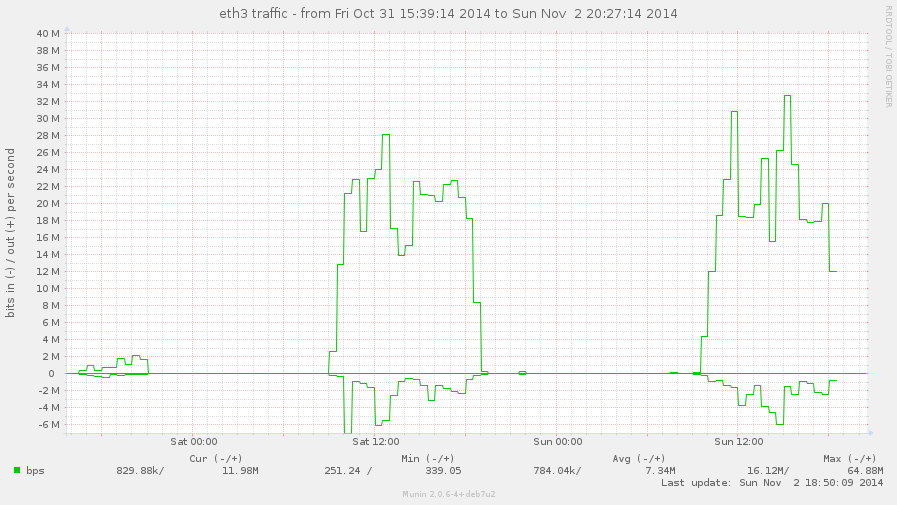
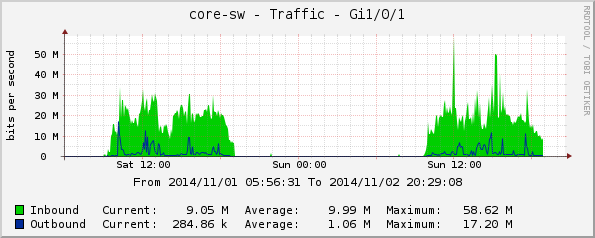
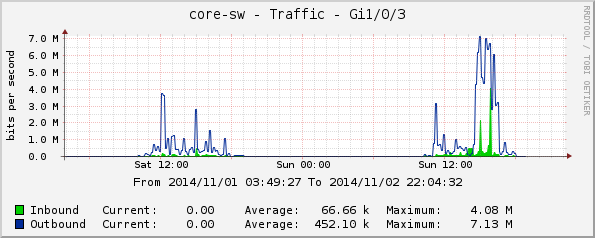
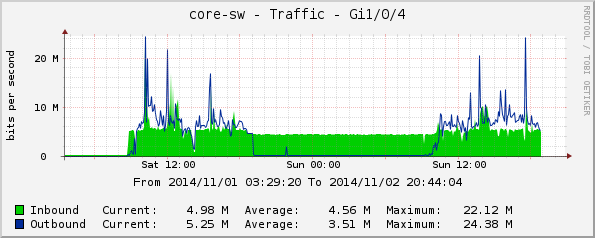
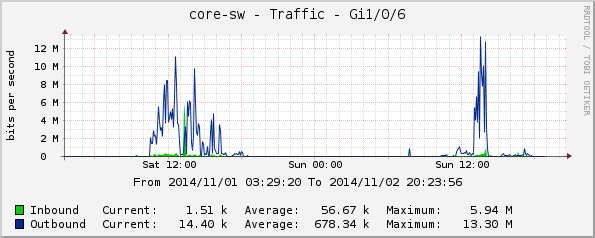
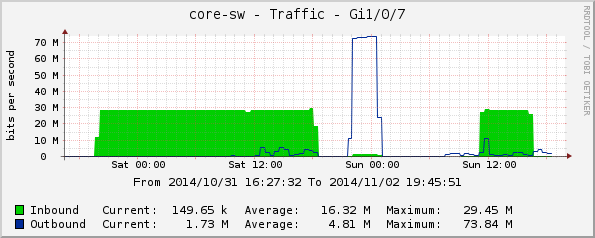
core-sw:
Gi1/0/1, вътрешен порт за потребителския трафик;
Gi1/0/2, streaming VLAN;
Gi1/0/3, зала Пловдив;
Gi1/0/4, зала София (джоб);
Gi1/0/6, зала Бургас;
Gi1/0/7, зала G1;
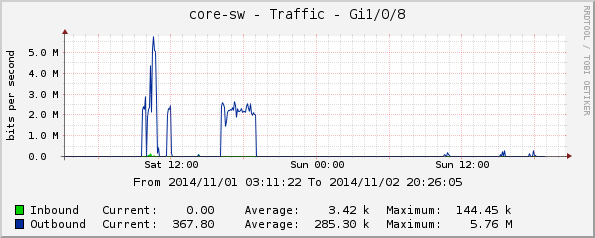
Gi1/0/8, зала G2;
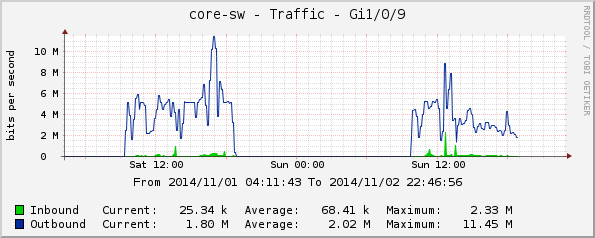
Gi1/0/9, зала G3;
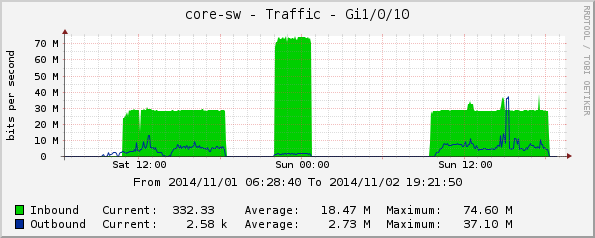
Gi1/0/10, зала Варна;
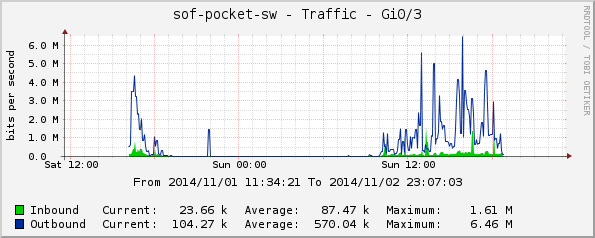
sof-pocket-sw:
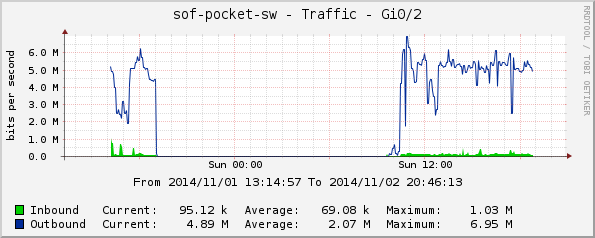
Gi0/2, рецепция на зала София;
Gi0/3, зала София, десен access point (OFAP02);
Gi0/4, зала София, ляв access point (OFAP00);
Уникални MAC адреси:
1 ноември – 557;
2 ноември – 553;
Общо за двата дни – 769;
MAC адреси по производител, първите 10 (благодарение на Точо, който го изсмята):
Apple 121
Samsung 108
Intel 93
LG 75
HTC 49
Murata 38
Sony 38
Hon Hai 32
Motorola 27
Nokia 24
Вдигането на мрежата мина нормално, само с няколко грешки (основно мои, липсващи vlan-и по switch-ове и някакви промени в последния момент). Кабелите бяха пуснати сравнително лесно, като за това помогна, че не ни беше за пръв път (Явор беше опъвал част от тях по същите места в предишните поне две години), а за останалите имахме достатъчно помощници и клещи. Само един switch беше конфигуриран там на място, тоя за зала Бургас, понеже тогава ни го дадоха (Пешо седя в един ъгъл с кратък списък изисквания от мен и го човърка). Въпреки някои забавяния, мисля, че самата мрежа беше съвсем по график и беше пусната най-лесно, въпреки относително многото хамалогия. Единствените неща, което настроих в петък вечерта в заведението, в което ядохме, бяха IPv6 (понеже не беше толкова приоритетно) и да добавя останалите устройства в icinga-та (която така и не гледахме).
Имахме няколко проблема по време на събитието:
Имаше доста broadcast трафик от arp пакети, за клиенти, които са били асоциирани, после са се разкачили и изчезнали от arp cache, но отвън още се опитват да им пратят нещо. Решението, което сглобих, беше да вадя списък на всички изтекли dhcp lease-ове (чрез някакъв perl скрипт, който намерих в github), и за всички тях чрез conntrack tool-а да трия всичкия им съществуващ state. Не съм сигурен доколко помогна, вероятно тоя broadcast не е бил толкова много така или иначе.
Имаше няколко случая на arp spoof, до които не се добрахме (срам);
В един момент решихме да вдигнем worker-ите на nginx-а на restreamer-а и се оказа, че просто rtmp модула не се оправя с повече от един worker. Това е нещо, което трябва да debug-на за в бъдеще.
И най-идиотския проблем – спираше ни ipv6. По някаква причина от време на време просто сървъра и спираше да отговаря на ipv6 пакети, и да ги route-ва, като все още нямам обяснение защо и не е проблем, който съм виждал където и да е другаде, но със сигурност поне 80% от оплакванията, че не работи wireless-а идваха от android телефони, които просто се опитваха да минават по v6. В списъка ми е да го проверя от какво може да е било, обмислям да изтормозя някой от съществуващите ми v6 router-и и да видя дали мога да го репродуцирам.
За следващия път съм си отбелязал следните неща:
Работещ ipv6 :) (Петко предлага да сме само по v6, но това не звучи като добра идея);
Да отделим хора за NOC, които да следят мрежата и да хващат проблеми (arp spoof-ове и т.н.);
По-подробен monitoring (който да го гледа NOC-а);
Никакви switch-ове и подобни, които отнемат над половин час, за да се подкарат;
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}