Мрежата на тазгодишния openfest беше с един порядък по-сложна от миналогодишната. Как вървят кабелите и в общи линии си личи на плановете на партера (първия етаж) и първи балкон (втори етаж).
(ще говоря за core мрежата само, Петко ще разказва за wireless-а)
Понеже самата зала България няма никаква мрежова инфраструктура, направихме мрежа от няколко свързани кръга (в стила на ISP) с MSTP в/у тях, така че да можем да се спасим от поне един паднал кабел. Решихме, че един гигабит ни стига за backbone и не правихме някакви по-сложни неща, като балансиране м/у няколко връзки.
Самата core мрежа имаше следните “клиенти”:
– router и encoder, при core switch-а;
– wireless мрежата;
– Видео екипите в трите зали;
– Рецепцията;
– switch-овете за крайни потребители в workshop залата, и
– две специално донесени железа от e-card, на които хората се записваха за томбола.
Тази година пак няколко човека ни услужиха с техника – Светла от netissat, Иван Стамов, Стефан Леков донесе един switch, digger даде двата за workshop-ите, и останалото дойде от мен и initLab. Също така настройването не го правих сам – Леков и Петко участваха активно в дизайна (и направиха прилична част от него), а Стоил, Марги и Zeridon – голямата част от конфигурацията на switch-овете.
Имахме 8 core switch-а на различни места, като където се налагаше да има switch в залите, се слагаше нещо по-тихо. Целият core беше от изцяло гигабитови switch-ове (като изключим един, който имаше и 10gbps портове, но не влязоха в употреба, за съжаление). Така можахме да закачим всичко извън тази мрежа на гигабит, включително wireless AP-тата, които тази година бяха изцяло гигабитови. Нямаше грешката от миналата година да се ползват супер-различни switch-ове – бяха 3 TP-Link SG-3210 и останалото леко разнообразни Cisco-та, като STP конфигурация с тях в тоя вид беше тествана още на курса по системна администрация (ето тогавашната схема).
Router ни беше един HP DL380G5, който в общи линии си клатеше краката (до момента, в който пуснахме да encode-ва един stream и на него). Тук нямаше особено много промени от миналата година, просто един linux-ки router с NAT и DNS/DHCP. По-забавните неща там бяха многото monitoring и записвания на данни (за които ще карам да се пише нещо отделно), в общи линии setup с collectd и събиране на каквито данни може да се събират.
Нямам в момента някакви снимки от мрежата, но беше опъната по най-добрия възможен начин за обстоятелствата – кабелите бяха прибрани и увити с велкро, нямаше някакви, през които да минават хора и като цяло не се виждаха особено много. Местат, които не бяха посещавани от хора бяха малко плашещи (например core switch-а, router-а и encoder-а бяха под едни стълби до едно ел. табло и изглеждаха като мрежовия вариант на клошари), но за останалите успяхме да намерим по-скрити и подходящи места (в workshop area-та switch-ът с няколко други неща беше под един роял).
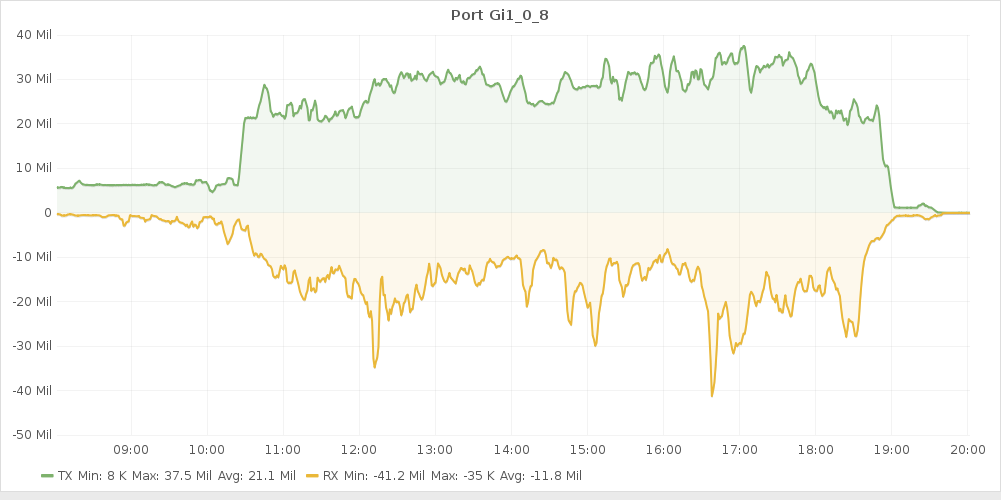
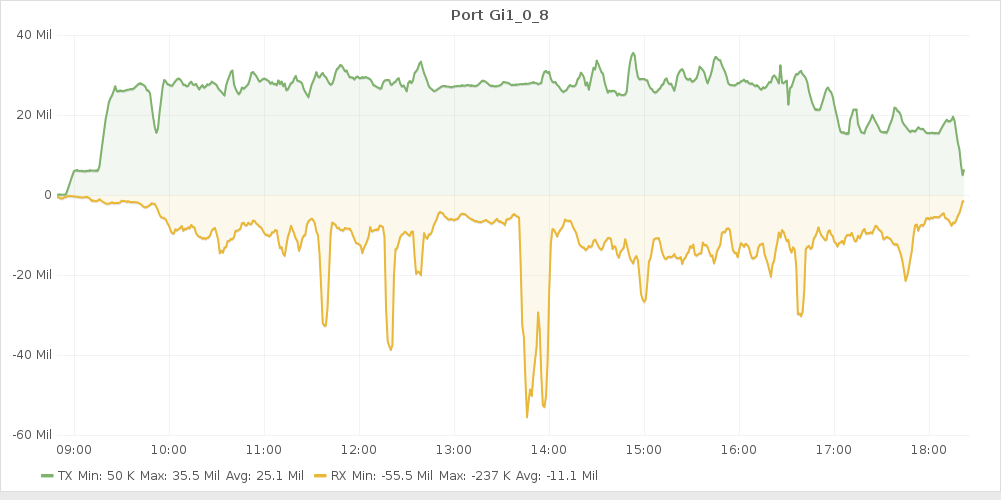
Internet-ът ни беше от Netx (които успяха да реагират в нормални срокове и да опънат оптика около месец преди събитието, за разлика от други, които ще останат неназовани), и тази година 100те mbps нещо почнаха да не ни стигат. Това са графиките от първия и втория ден, като прилична част от изходящия беше streaming-а. Проблемите се виждат на графиката на smokeping-а, и поне според мен за по-спокойно догодина трябва да сме на 200mbps.
Адресният план беше много близък до миналогодишния:
VLAN 50 – външната ни връзка, 46.233.38.137/28 и 2a01:b760:1::/127
VLAN 100 – нашата си management мрежа, 10.100.0.0/24
VLAN 101 – мрежата за хората, свързани на кабел, 10.101.0.0/22, 2a01:b760:abc:2::/64
VLAN 102 – мрежата за хората, свързани на wireless-а, 10.102.0.0/22, 2a01:b760:abc:3::/64
VLAN 103 – мрежата на видео-екипа, 10.103.0.0/24
VLAN 104 – мрежата на overflow телевизорите, 10.104.0.0/24
(нещо, което не трябва да пропускаме за догодина е да раздадем адреси на видео-оборудването предварително, сега те си ги измисляха в последния момент и аз просто разместих раздавания range от dhcp-то)
Firewall-ът беше тривиален, от типа на “тия всичките vlan-и не могат да си говорят помежду си, само с външния” и “25ти порт е забранен”. Не съм голям фен на stateful нещата за такива случаи, а тоя прост setup свърши прекрасна работа.
Пуснали бяхме и още нещо странно – освен филтрацията на broadcast трафика, бяхме включили за потребителските vlan-и (101, 102) proxy_arp_pvlan, което в общи линии е poor man’s forced forwarding – караше router-а да отговаря със себе си за всички arp заявки. Така се избягваше прилично количество broadcast, затрудняваше се arp spoofing-а (с няколкото други неща директно и се убиваше) и като цяло не направи някакъв проблем, освен че може би държеше пълен arp cache на windows машините.
Преди събитието имахме няколко проблема. Един от тяхбеше, че не бяхме предвидили вярно колко кабел ни трябва, и се наложи спешно да се купи още един кашон (300м), но като цяло мрежата изгря без проблеми, може би с една-две грешки по конфигурацията на портовете. Също така един от switch-овете (cisco ws-3550-12G) имаше проблеми с gbic-ите, понеже няколко от медните не работеха, та за това имахме 5м оптика – един от access point-ите беше свързан през single-mode gbic в switch-а и конвертор от другата страна. За дебъгване имаше един вечерта, като закачахме на e-card машините, за които се оказа, че един странно прекъснат кабел прави нещата да не работят, но имаше link (това се усети най-вече по това, че не щяха да закачат на гигабит).
По време на събитието пак имахме проблем с ipv6, този път обаче след нашия router, и понеже нямахме как да го debug-нем/решим, втория ден бяхме ipv4-only. Бяхме правили тестове предишната седмица с връзката, но явно някакви неща не сме успели да ги хванем (или нашия router пак е направил нещо странно). Също така по погрешка бяха извадили тока на един switch (което аз поне изобщо не съм усетил), и заради кофти удължител за малко е паднало едно AP (което е било хванато моментално на monitoring-а).
Като цяло, мрежата избута всичките си неща без никакъв сериозен проблем и потребителски оплаквания тая година нямаше.
Ще оставя статистиките и другите неща на хората, дето ги събираха :)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}